التحكم بانظمة الذكاء الاصطناعي الفائق: و اولى الحلول المقترحة
التطور المتسارع في انظمة الذكاء الاصطناعي في الآونة الاخيرة خاصة في عام 2023،وتسابق الشركات التقنية للكسب المادي منه مثل جوجل ومايكروسوفت وادوبي وOpen AI دون التفكير في عواقب الذكاء الاصطناعي الفائق. تسبب بذعر وهلع لدي بعض رواد التقنية الذين ينظرون لابعد من الكسب المادي. ومن ابرزهم رائد الاعمال ومالك شركة Open AI الرائدة في مجال الذكاء الاصطناعي ايلون ماسك.
هذا التخوف من الذكاء الاصطناعي ادى الى حادثة شهيرة في 29 مارس 2023. حيث قام اكثر من الف شخص من مختصي التقنية من بينهم ايلون ماسك، بتوقيع ورقة مطالبين فيها بايقاف تطوير انظمة الذكاء الاصطناعي اقوى من نظام Chat GPT-4 الذي صدر في 14 مارس 2023 لمدة ستة شهور. حتي يجدو حلا لامكانية التحكم بهذه الانظمة القوية في المستقبل ثم المواصلة في تطوير انظمة الذكاء الاصطناعي.
ولكن هذا الطلب تم رفضه من قبل الشركات التقنية، بسبب العائد المادي الذي تجنيه هذه الشركات من الذكاء الاصطناعي. وقالو مقدمي هذا الطلب يجب على الحكومات ان تتدخل الايقاف هذه الشركات من التقدم اكثر في هذا المجال الى اشعار آخر.
ولكن ايلون ماسك لم يقف عند هذا الحد. بل قامت الشركة المملوكه له Open AI في 5 يوليو 2023 باعلان تشكيل فريق من مهندسين وباحثين في مجال التعلم اللآلي. لحل مشكلة التحكم بالانظمة الذكاء الاصطناعي الفائق في خلال 4 سنوات قادمة.
وسمي بفريق المحاذاة الفائفة (Superalignment team). المحاذاة الفائقة مصطلح يعنى به التحكم بانظمة الذكاء الاصطناعي الفائق، الذي يفوق ذكائة ذكاء البشر. انظر مقال ماهي المحاذاة الفائقة في الذكاء الاصطناعي .
اول ورقة بحثية قدمها الفريق في مسألة المحاذاة الفائقة
حيث قدم الفريق ورقة بحثية اولية في 31 يناير 2024. بعنوان (التعميم من القوي للضعيف) تمثل اتجاهًا بحثيًا جديدًا للمحاذاة الفائقة. تطرح سؤال هل يمكننا الاستفادة من خصائص التعميم للتعلم العميق للتحكم والاشراف في النماذج القوية للذكاء الاصطناعي عن طريق نمازج ذكاء اصطناعي الضعيفة؟ وكانت لهم نتائج أولية وتجارب واعدة.
حيث أظهرو أنه يمكننا استخدام نموذج ضعيف من المستوى GPT-2 لاستنباط معظم قدرات GPT-4 – او كل القدرات من مستوى GPT-3.5 -. والتعميم بشكل صحيح حتى على المشكلات الصعبة التي فشل فيها النموذج الصغير. وهذا يفتح اتجاهًا بحثيًا جديدًا يسمح لنا بمعالجة التحدي الرئيسي المتمثل في مواءمة النماذج المستقبلية الخارقة مع تحقيق تقدم تجريبي متكرر اليوم بشكل مباشر.
يتمثل التحدي الأساسي لمواءمة أنظمة الذكاء الاصطناعي الخارقة المستقبلية (المحاذاة الفائقة) في أن البشر سيحتاجون إلى الإشراف على أنظمة الذكاء الاصطناعي بشكل أكثر ذكاءً منهم. نحن ندرس تشبيهًا بسيطًا: هل يمكن للنماذج الصغيرة أن تشرف على النماذج الكبيرة؟
مشكلة المحاذاة الفائقة في التحكم بانظمة الذكاء الفائق
نحن نؤمن بإمكانية تطوير الذكاء الفائق – الذكاء الاصطناعي الأكثر ذكاءً من البشر – في غضون السنوات العشر القادمة. ومع ذلك، ما زلنا لا نعرف كيفية توجيه أنظمة الذكاء الاصطناعي الفائق والتحكم فيها بشكل موثوق. يعد حل هذه المشكلة أمرًا ضروريًا لضمان أن تظل أنظمة الذكاء الاصطناعي الأكثر تقدمًا في المستقبل آمنة ومفيدة للبشرية.
بالنسبة لنماذج الذكاء الاصطناعي الخارقة، سيكون البشر “مشرفين ضعفاء”. وهذا هو التحدي الأساسي الذي يواجه مواءمة الذكاء الاصطناعي العام. كيف يمكن للمشرفين الضعفاء أن يثقوا في النماذج الأقوى ويتحكموا فيها؟
لقد قمنا بتشكيل فريق Superalignment في وقت سابق من هذا العام لحل مشكلة محاذاة الذكاء الفائق هذه. واليوم، نصدر الورقة الأولى للفريق، والتي تقدم اتجاهًا بحثيًا جديدًا لمواءمة النماذج الخارقة تجريبيًا.
كيف يتم التحكم بانظمة الذكاء الاصطناعي الحالية؟
تعتمد أساليب المحاذاة الحالية اي التحكم بانظمة الذكاء الاصطناعي الحالية،على الاشراف البشري. مثل التعلم المعزز من ردود الفعل البشرية (RLHF). ولكن أنظمة الذكاء الاصطناعي المستقبلية ستكون قادرة على القيام بسلوكيات معقدة للغاية ومبتكرة. ستجعل من الصعب على البشر الإشراف عليها بشكل موثوق. على سبيل المثال، قد تكون النماذج البشرية الخارقة قادرة على كتابة ملايين الأسطر من أكواد حاسوبية جديدة – وربما خطيرة – والتي سيكون من الصعب جدًا حتى على البشر الخبراء فهمها.
الحلول المقترحة حاليا
لتحقيق تقدم في هذا التحدي الأساسي، نقترح تشبيهًا يمكننا دراسته تجريبيًا اليوم. وهواستخدام نموذج أصغر (أقل قدرة) للإشراف على نموذج أكبر (أكثر قدرة)؟

تشبيه بسيط للمحاذاة الفائقة: في التعلم الآلي التقليدي (ML)، يشرف البشر على أنظمة الذكاء الاصطناعي الأضعف منهم. ولكن لمواءمة الذكاء الفائق، سيحتاج البشر بدلاً من ذلك إلى الإشراف على أنظمة الذكاء الاصطناعي الأكثر ذكاءً من البشر. لا يمكننا دراسة هذه المشكلة بشكل مباشر اليوم. ولكن يمكننا دراسة تشبيه بسيط: هل يمكن للنماذج الصغيرة الإشراف على النماذج الأكبر (صحيح)؟
ومن السذاجة أننا قد لا نتوقع أن يؤدي النموذج القوي أداءً أفضل من المشرف الضعيف الذي يوفر إشارة التدريب الخاصة به – فقد يتعلم ببساطة تقليد جميع الأخطاء التي يرتكبها المشرف الضعيف.
ومن ناحية أخرى، تتمتع النماذج القوية المدربة مسبقًا بقدرات أولية ممتازة . فنحن لا نحتاج إلى تعليمهم مهام جديدة من الصفر، بل نحتاج فقط إلى استخلاص معرفتهم الكامنة. السؤال الحاسم إذن هو: هل سيتم تعميم النموذج القوي وفقًا للقصد الأساسي للمشرف الضعيف – مع الاستفادة من قدراته الكاملة لحل المهمة حتى في المشكلات الصعبة. حيث لا يستطيع المشرف الضعيف سوى تقديم مسميات تدريب غير مكتملة أو معيبة؟
النتائج التي تم التوصل اليها
تجربة تعتمد على تعميم نموذجي من نموزج ضعيف إلى نموزج قوي عبر معايير البرمجة اللغوية العصبية. مثلا نستخدم نموذج مستوى GPT-2 كمشرف ضعيف لضبط مستوي GPT-4القوي.
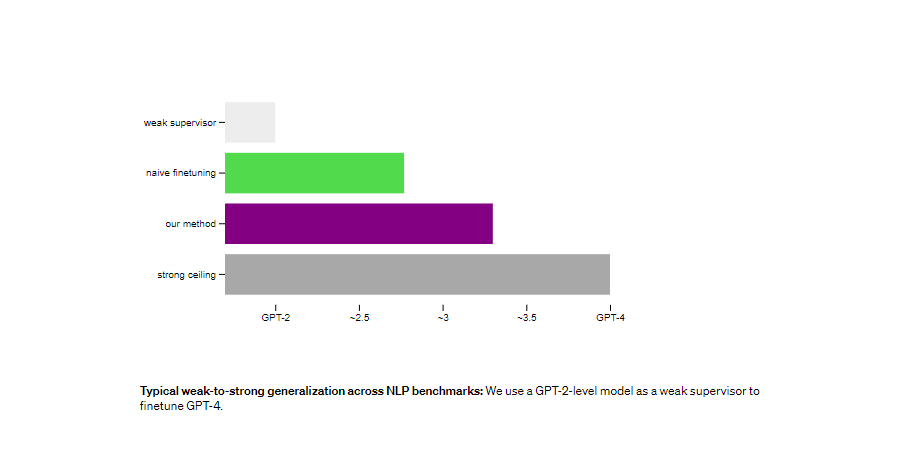
يمكننا تحسين التعميم بشكل كبير في العديد من الإعدادات. نحن نستخدم طريقة بسيطة تشجع النموذج القوي على أن يكون أكثر ثقة. بما في ذلك الاختلاف بثقة مع المشرف الضعيف إذا لزم الأمر. عندما نشرف على GPT-4 باستخدام نموذج من مستوى GPT-2 باستخدام هذه الطريقة في مهام البرمجة اللغوية العصبية، فإن النموذج الناتج يؤدي عادةً في مكان ما بين GPT-3 وGPT-3.5. نحن قادرون على استعادة الكثير من قدرات GPT-4 بإشراف أضعف بكثير.
هذا الأسلوب هو دليل على المفهوم مع قيود هامة؛ على سبيل المثال، لا يزال لا يعمل على بيانات تفضيلات ChatGPT. ومع ذلك، فإننا نجد أيضًا علامات للحياة مع أساليب أخرى. مثل التوقف المبكر الأمثل والتمهيد من النماذج الصغيرة إلى المتوسطة إلى الكبيرة.
بشكل جماعي، تشير نتائجنا إلى أن (1) الإشراف البشري الساذج – مثل التعلم المعزز من ردود الفعل البشرية (RLHF) . يمكن أن يتوسع بشكل سيئ ليشمل النماذج الخارقة دون مزيد من العمل. ولكن (2) من الممكن تحسين التعميم من الضعيف إلى القوي بشكل كبير .
فرص وتحديات البحث في المستقبل
لا تزال هناك تناقضات مهمة بين إعدادنا التجريبي الحالي والمشكلة النهائية المتمثلة في مواءمة النماذج الخارقة. على سبيل المثال، قد يكون من الأسهل على النماذج المستقبلية تقليد الأخطاء البشرية الضعيفة. مقارنة بالنماذج القوية الحالية لتقليد أخطاء النماذج الضعيفة الحالية، مما قد يجعل التعميم أكثر صعوبة في المستقبل.
ومع ذلك، نعتقد أن إعدادنا يجسد بعض الصعوبات الرئيسية في مواءمة النماذج المستقبلية الخارقة. مما يمكننا من البدء في تحقيق تقدم تجريبي بشأن هذه المشكلة اليوم. هناك العديد من الاتجاهات الواعدة للعمل في المستقبل، بما في ذلك إصلاح التناقضات في إعدادنا، وتطوير أساليب أفضل قابلة للتطوير. وتعزيز فهمنا العلمي لمتى وكيف ينبغي لنا أن نتوقع تعميماً جيداً من الضعيف إلى القوي.
دعوة ومنح لكل للمطورين للمساهمة في البحث
تعد محاذاة الذكاء الاصطناعي الفائق واحدة من أهم المشكلات التقنية التي لم يتم حلها في عصرنا. وتقول الشركة نحن بحاجة إلى أفضل العقول في العالم لحل هذه المشكلة.
نعتقد أن هذه فرصة مثيرة لمجتمع أبحاث تعلم الآلة لإحراز تقدم في المواءمة. لبدء المزيد من الأبحاث في هذا المجال،
- سيتم اصدار تعليمات برمجية مفتوحة المصدر لتسهيل البدء بتجارب التعميم الضعيفة إلى القوية اليوم.
- ايضا نطلق برنامج منح بقيمة 10 ملايين دولار. لطلاب الدراسات العليا والأكاديميين وغيرهم من الباحثين للعمل على مواءمة الذكاء الاصطناعي الخارق على نطاق واسع.
إذا كنت ناجحًا في التعلم الآلي، ولكنك لم تعمل على المحاذاة من قبل، فهذا هو الوقت المناسب لإجراء التبديل! نعتقد أن هذه مشكلة تعلم آلي سهلة الحل، ويمكنك تقديم مساهمات هائلة في هذا المجال الجديد الواعد.
الخاتمة
إن معرفة كيفية مواءمة أنظمة الذكاء الاصطناعي الفائق المستقبلية لتكون آمنة لم تكن أكثر أهمية من أي وقت مضى. وأصبح الآن من الأسهل من أي وقت مضى تحقيق تقدم تجريبي في هذه المشكلة. نحن متحمسون لرؤية الاكتشافات التي اكتشفها الباحثون.